📓 Linked Lists
In this lesson, we are going to cover a data structure called a linked list. A linked list is a collection of elements that's very different than an array because its elements are not indexed. Instead, a linked list is a collection of nodes that are linked together. Linked lists are commonly either singly linked or doubly linked. In a singly linked list, each element has a link to the next element in a list. In a doubly linked list, each element has a link to both the prior element and the next element.
Here's a depiction of a linked list with three nodes:
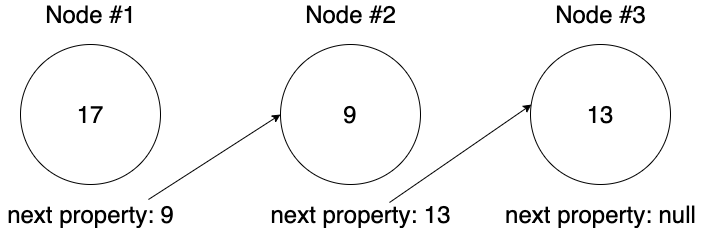
In this simple depiction, each node has a numerical value (its data) and a next property. The first node is the head. The node's next property is what links it to the next node. In other words, a reference to the next node is stored in the previous node. As you can see, the final node has a next property of null because there is no node after it that it can link to.
In a doubly-linked list, each node would have a previous property, too. In a singly-linked list like the one depicted above, we can only navigate the linked list sequentially moving forward — nodes have no knowledge of the node that's before them, only the ones that come next. It's like being in a conga line where you can only see the person in front of you — not the person behind you.
A linked list can be ordered or unordered. The linked list above is unordered because the values don't increase sequentially.
Advantages of Linked List
Why would we ever use a linked list? What advantage do they have over arrays? Well, it is generally more efficient to insert and remove elements in a linked list than in an array. We'll discuss why in a moment. However, a linked list must sequentially go through an array using each node's reference to find the next node. For that reason, it is not efficient to search linked lists. It's the equivalent of doing a linear search from the beginning to the end of an array. The difference with arrays is that there are lots of other effective search algorithms we can use (such as a binary search algorithm) to make searching more efficient.
The advantages of linked lists are more obvious in lower-level languages — so why should we bother to learn this data structure when we have focused on high-level languages at Epicodus? Is there any good reason to learn about them other than the fact that they are considered an essential computer science concept for programmers to know about?
Well, linked lists can have applications in front end JavaScript (even if we might not need to directly create linked lists ourselves). One key example is React's algorithms for rendering graphics, which use linked lists.
So why is it faster to insert and remove elements from a linked list than an array?
Well, when we add a node to a linked list, we only need to change two small things to add the node:
- The
this.nextproperty of the new node will become the previous node'sthis.nextproperty. - The
this.nextproperty of the previous node needs to be updated to reference the new node.
So imagine that we insert a node at the head of a linked list that has one million elements. Only two small things need to be changed. On the other hand, if we added an element to the first position of an array, all one million elements that come afterwards must be reindexed. JavaScript will take care of this for us — but it won't be nearly as efficient as changing a single node.
The same thing is true if we remove a node. We only need to change one thing to remove a node in a linked list:
- The node before the node to be deleted needs a small update: its
this.nextproperty needs to be updated tothis.next.next, which is the node that comes directly after the deleted node. We are essentially removing a link from the middle of a chain and then reattaching the link that came before and after the link that's been removed.
Once again, this is much more efficient than the same process in an array.
Let's say, for instance, we are creating an application where we occasionally completely re-render a page. All the elements of that page are stored in an array. Because we'd need to walk through every element in the array anyway (since we are doing a complete re-rendering), this could be a great opportunity for a linked list. Again, because this is a full re-rendering, there's also no need to search the nodes — yet another bonus point for using a linked list instead of an array. It should be clearer now why React developers took this path for rendering graphics more quickly.
As you've probably guessed, we need to be very careful when removing a node from a linked list. If we don't properly attach the previous node to the node that comes after the removed node, we'll lose all the data that comes after the removed node.
Building a TDD Linked List Application
Let's look at a basic JavaScript implementation of a linked list. We'll use a test-driven approach to construct our code.
Our code will have two classes: Node and LinkedList. An instance of LinkedList will be made up of instances of linked Nodes. We'll write methods for adding a node to the end of a linked list and removing a node based on its index. At the end of this lesson, there will be an exercise where you can test and write a few additional methods on your own.
Here's the structure of our project:
.vscode
__tests__
|- linked-list.test.js
|_ node.test.js
src
|-linked-list.js
|_ node.js
.babelrc
.gitignore
package.json
Testing and Writing a Node Class
Let's start with our Node class. It's not going to need much — just a constructor. We will keep that constructor very simple. Here's a test:
import Node from '../src/node.js';
describe('Node', () => {
test('should correctly create a node', () => {
const node = new Node("head");
expect(node.data).toEqual("head");
expect(node.next).toEqual(null);
});
});
When a node is constructed, it should have some data. It will also have a next property, though the linked list will take care of setting that up that relationship with other nodes. A node could certainly have a lot more information than this but we'll keep it simple so we can focus on the basic concepts.
Now let's get this test passing:
export default class Node {
constructor(data) {
this.data = data;
this.next = null;
}
}
That is all we need from our Node class. Our LinkedList class will take care of everything else.
It should be clear from the constructor that this is a singly-linked list since there is a next property but no previous property.
Instantiating a Linked List
Now we're ready to start coding our LinkedList class. As always, we'll start with the simplest possible behavior. A linked list has a head node — this is the first node in the linked list. That means when we instantiate a linked list, it should include this head property.
Here's a test:
import LinkedList from '../src/linked-list.js';
describe('LinkedList', () => {
test('it should construct a linked list with a head property', () => {
let linkedList = new LinkedList();
expect(linkedList.head).toEqual(null);
});
});
Our test is just going to check if a constructed linked list has a head property set to null. It will be null because it's an empty linked list.
Here's the constructor to get this test passing:
export default class LinkedList {
constructor() {
this.head = null;
}
}
The first node that is added to an empty list will become the head. Because the head is the reference point for every other node in a linked list, it's important to be very careful about changing it, especially if different developers need access to the head. For that reason, it's common to make the head immutable by declaring it as a symbol. A symbol is a primitive data type that is immutable. We aren't working with other developers here, though, and we'll stay focused on the basic concepts of a linked list, which means we won't do anything special with the head node.
Based on this information, it should be clear what needs to happen next. When a node is added to an empty linked list, that node needs to become the head.
Adding a Head Node to a Linked List
Here's a test:
...
test('LinkedList.prototype.insertLast() should add a node at head if a linked list has no head', () => {
let linkedList = new LinkedList();
linkedList.insertLast("head");
expect(linkedList.head.data).toEqual("head");
});
...
We're calling our insertion method LinkedList.prototype.insertLast(data) because it will always insert a node at the end of the list. That means we'll need to traverse through each node to find the final node to link a new node to. But we aren't there yet! That's why we are using TDD — to build this up in a simple, manageable way.
So what is the simplest implementation to get our new test passing?
// We'll need to import the Node class so our LinkedList class can instantiate nodes in a linked list.
import Node from './node.js';
export default class LinkedList {
constructor() {
this.head = null;
}
insertLast(data) {
const newNode = new Node(data);
this.head = newNode;
}
}
As you can see, our first implementation is very simple. We instantiate a new node with data that the user passes in. Then we set this.head equal to that new node. Our list now has a reference point!
Inserting a Node in a Populated Linked List
So now we are ready for the next behavior. We need to be able to insert a node after the head node. That means we have to traverse the linked list. We can't rely on a built-in method like Array.prototype.push() to add the node.
Let's write the test now. We're also going to add a beforeEach() and afterEach() block to clean up our tests a bit.
import LinkedList from '../src/linked-list.js';
describe('LinkedList', () => {
let linkedListWithNodes = new LinkedList();
beforeEach(() => {
linkedListWithNodes.insertLast("node1");
linkedListWithNodes.insertLast("node2");
linkedListWithNodes.insertLast("node3");
linkedListWithNodes.insertLast("node4");
});
afterEach(() => {
linkedListWithNodes.head = null;
});
...
test('LinkedList.prototype.insertLast() should add a node at the end of a linked list', () => {
linkedListWithNodes.insertLast("new last");
expect(linkedListWithNodes.head.next.next.next.next.data).toEqual("new last");
});
});
We start by creating a new instance of LinkedList called linkedListWithNodes that will be available for our tests. Our beforeEach() block will add three nodes to linkedListWithNodes. Then our afterEach() block will set linkedListWithNodes.head = null;. This is just some clean up — removing the head of a linked list is the equivalent of deleting it! This way, we can make sure there's no remnant of the linked list from one test polluting the next test.
Now for the test itself. Our method should add a node at the end of our instantiated linked list — since our linked list already has three nodes, this update to our test will verify that LinkedList.prototype.insertLast() correctly traverses the linked list to the final node and then links a new node to it. linkedListWithNodes.head.next.next.next.next.data — but that is the way we'd verify that our new node has been added at the fifth position of the linked list!
Fortunately, traversing a linked list is pretty simple. Here's our updated method:
...
insertLast(data) {
const newNode = new Node(data);
if (this.head === null) {
this.head = newNode;
} else {
let currentNode = this.head;
while (currentNode.next != null) {
currentNode = currentNode.next
}
currentNode.next = newNode;
}
}
The first three lines of code are essentially the same — we just need to add a conditional so this.head is only updated if the list is empty.
Now let's look at the code in the else statement.
- A journey of a thousand nodes begins with a single step — so we need to start at the head node. We'll create a new variable called
currentNodewhich is set tothis.head. - Next, we need to traverse the linked list to the end. We'll do this with a while loop. The loop will run while
currentNode.next != null. It will take thecurrentNode.nextproperty and updatecurrentNodeto equal thenextnode. That way, we can traverse the linked list untilcurrentNode.nextisnull. At that point, we know we've reached the end of the linked list because there isn't a node atcurrentNode.next.
So the loop ends when currentNode is the final node . We simply need to set the currentNode.next property to our newly created node to add it to the list.
If we run our test, we'll see it passes.
Now we're ready to move onto testing and writing a method for removing a node.
Removing a Node from a Linked List
Removing a node from a linked list is a little more involved. Why is that? Well, in the method we've already written, we just need to keep track of the current node and keep traversing until currentNode.next is null.
We will still need to keep track of the current node when we remove an item from a linked list. Because the nodes in our linked list aren't indexed and we will be removing a node based on its index, we'll need to keep track of the index, too.
Let's start with a test. Our method will be called LinkedList.prototype.remove(indexToRemove) and will take the index we want to remove as an argument. What's the simplest possible behavior we can add? Let's write a test for removing and updating the head. This is a simpler behavior than removing another node because it doesn't require any traversal.
...
test('it should set a new head if the head is removed', () => {
linkedListWithNodes.remove(0);
expect(linkedListWithNodes.head.data).toEqual("node2");
});
...
The first position of the linked list will be 0 just as it is with an array. When the first position is removed, we'll expect the data property of the linked list's head property to be "node2" instead of "node1".
Now let's get this test passing:
...
remove(indexToRemove) {
this.head = this.head.next;
}
...
All we have to do is set this.head to be equal to this.head.next. That cuts the first node out of the list entirely.
Now we are ready for our next test. We should be able to traverse the linked list and remove a node.
...
test('it should remove a node from the middle', () => {
linkedListWithNodes.remove(2);
expect(linkedListWithNodes.head.next.next.data).toEqual("node4");
});
...
Remember that linkedListWithNodes is set up in our beforeEach() block with four nodes. In this test, we are removing the third node — and then checking to see if the new third node is equal to the previous fourth node. That will verify the old third node has been removed.
Now let's update our method to get the test passing:
remove(indexToRemove) {
if (indexToRemove === 0) {
this.head = this.head.next;
} else {
let currentNode = this.head;
let currentIndex = 0;
while ((currentIndex +1) <= indexToRemove) {
if ((currentIndex + 1) === indexToRemove) {
currentNode.next = currentNode.next.next;
break;
}
currentNode = currentNode.next;
currentIndex++;
}
}
}
First, we have to set up a conditional so this.head is only modified if the index to be removed is 0.
Otherwise, we'll start traversing. Just as with our LinkedList.prototype.add(data) method, we'll set a currentNode variable equal to this.head. We'll also set up a currentIndex method which is specific to this method since our linked list isn't indexed.
Now let's look at our loop, which will run as long as the (currentIndex + 1) <= indexToRemove. Why the +1? Well, remember that our linked list only knows about the node that comes next — not the one that comes before it. However, once we get to the node we want to remove, we need to make an update to the node that comes before it.
There are two approaches to solving this. One is to just have a previousNode variable that provides a pointer so we always have access to the previous node. However, this isn't necessary. When (currentIndex + 1) === indexToRemove, we know that we've reached the node that's directly before the node we want to remove. So instead of traversing all the way to the node we want to remove, we'll stop our traversal at the node before it instead. Then we just need to update that node's next property to currentNode.next.next — which cuts the node we want to remove out of the linked list. At this point, we can break out of the loop because are done.
If we haven't reached the node directly before the one we want to remove yet, we'll traverse to the next node and increment the currentIndex by 1:
currentNode = currentNode.next;
currentIndex++;
If we run our test, it will be passing.
What If the Index to Remove Doesn't Exist?
There's one more important problem we need to consider. What happens if the index doesn't exist in the linked list? Our method should return -1 if this is the case. (Alternatively, we could choose to throw an error.)
Let's write a test:
...
test('it should return -1 if the index does not exist', () => {
expect(linkedListWithNodes.remove(9)).toEqual(-1);
});
...
There's no 9th position in this linked list. Once we verify the test is properly failing, let's get it passing. Here's the full method:
remove(indexToRemove) {
if (indexToRemove === 0) {
this.head = this.head.next;
} else {
let currentNode = this.head;
let currentIndex = 0;
while ((currentIndex +1 ) <= indexToRemove) {
if (currentNode.next === null ) {
return -1;
}
if ((currentIndex + 1) === indexToRemove) {
currentNode.next = currentNode.next.next;
break;
}
currentNode = currentNode.next;
currentIndex++;
}
}
}
The only update is the following conditional inside the while loop:
if (currentNode.next === null ) {
return -1;
}
If we reach a node that has no next node and we still haven't found the index yet, we know the index is out of range and doesn't exist. Our method will return -1 and our test will pass.