📓 4.4.0.15 Structuring Data in Firestore
Just because NoSQL is flexible about structuring data doesn't mean we should just throw documents in a NoSQL database as if it were a junk drawer. We can actually use Firestore to structure data in many different ways. Even though we don't need a schema or database tables, we can still carefully plan how our data will be structured. In a real-world application, this is absolutely essential. SQL's more rigid rules force us to plan ahead of time while NoSQL removes the guardrails — which will leave us open to headaches down the road if we don't have a good plan.
For your multi-day projects in this course section, you may need to create more complex data structures for your application to function correctly. In this lesson, we will discuss three different ways to structure Firestore data. These ways are outlined in the Firebase documentation as well.
Let's imagine we are building an application with information on hiking trails in the Pacific Northwest. We want to have the following data on each trail:
namedescriptionregionreviews
In a SQL database, we'd probably have a table called Trails and another table called Reviews. A trail could have many reviews while a review would belong to a single trail. Since our application would likely have users as well, a review would probably also belong to a user — but for our use case, we won't worry about that. Potentially, we could have another table called Regions — a region could have many trails and a trail could belong to a single region.
However, we need to think about our data differently with NoSQL in general, and Firestore in particular. The considerations we'll discuss here are specific to Firestore, but knowing the advantages and limitations of each approach with Firestore can also be helpful for planning other NoSQL database structures in the future.
Nesting Data in a Single Document
Documents in Firestore are sets of key-value pairs. They look like JSON objects — though it would be more accurate to use the more general term map to describe them. A map is a set of key-value pairs. For that reason, we can theoretically store all of the data for a trail in a single document. Here's an example of how that data structure might look:
1: {
name: "Enchantments Trail",
region: "Enchantments",
description: "23.6 mile trail through Enchantments near Leavenworth, WA.",
reviews: {
1: {
content: "Amazing!"
},
2: {
content: "Very challenging hike."
},
}
}
In the example above, reviews is nested inside this document. We could, if we wanted, nest even more deeply.
The problem here, at least for the application we are talking about building, is obvious: these documents are going to get huge if there are a lot of reviews. This leads to several issues. There is an upper limit on the size of a Firestore document (1 megabyte or 20,000 fields). That's actually a fair amount of data — but our documents would run out of space pretty quickly in a large application.
There's another big disadvantage. We can't just query part of a document. If we query a document, we return the whole thing — warts and all. We might just want to return the ten most popular reviews but we won't be able to do that.
On the other hand, there are some use cases where the data structure above could work. If we know the data won't expand too much (as it will with reviews) and we also know that we always want to return all the data stored in a document — the structure above could be beneficial because we wouldn't have to make multiple queries to get all the data associated with a trail.
Enterprise applications will rarely go this route, but you may have a smaller application or a portfolio idea that could benefit from nesting data in a single document. Think carefully before you take this approach, though!
Advantages: Easy to get data related to a document because it's all stored in the same place.
Disadvantages: Doesn't scale well — and not recommended when data associated with a document will expand over time. This also isn't performant because there is a limit to the number of read and writes that can be made to a single document at a time.
Adding Subcollections to Documents
Students familiar with SQL databases might be tempted to try to recreate one-to-many relationships in Firestore. In some ways, adding a subcollection most closely mirrors creating a one-to-many relationship. However, it's not really the same.
A document can have its own subcollections. In fact, we can easily add a subcollection to our Help Queue project via the Firestore database UI:
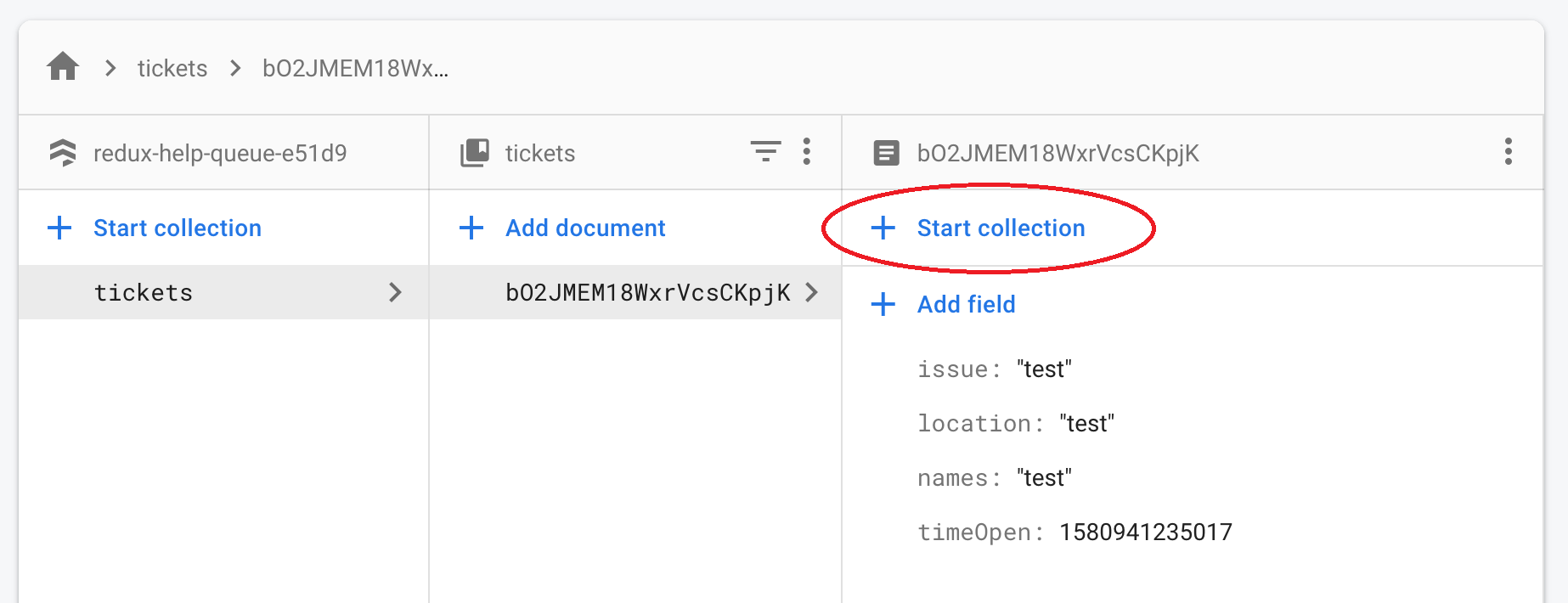
In the example above, we could click on a ticket from our Help Queue database, then click on "Start collection" (circled in red in the image above) in the rightmost panel to add a collection to that document. This wouldn't just be a collection, it would be a subcollection within the tickets collection.
If we used a subcollection in our Firestore database for our application about hiking trails in the Pacific NorthWest, it would make the most sense to make trails reviews a subcollection of a trail document. This structure would look something like this:
1: {
name: "Enchantments Trail",
region: "Enchantments",
description: "23.6 mile trail through Enchantments near Leavenworth, WA.",
}
Reviews Subcollection (belongs to "Enchantments Trail")
1: {
content: "Amazing!"
},
2: {
content: "Very challenging hike."
}
Firestore lists this as a feasible approach but we don't recommend it. Firestore can only query a single collection at a time, so to get a subcollection, we'd need to make two queries: one for the trail, and then another one for the reviews. So, if we wanted to find all the trail reviews by a specific user, for example, we definitely wouldn't be able to do that with a single query.
This is because Firestore queries are always shallow. They only return the top level of data, not subcollections. We can take advantage of this, however, if we design our application to only display the trails data without the reviews. In another page we could show the reviews, but only if the user navigates there. Separating this out could indeed make our application more performant since each database query would take less time.
In our case, this probably wouldn't be much of an advantage, though — and the pain of trying to query across multiple collections would be a huge disadvantage.
Another issue with this approach is writing the code for creating subcollections. The documentation on this is not extensive. However, let's say we wanted to have a subcollection of reviews for a specific trail. To add a review to the Enchantments Trail, we'd have to do something like this:
await addDoc(collection(db, "trails", "q2WkYeRXEZWoG0EnTzkh", "reviews"), newReviewData);
Note that "q2WkYeRXEZWoG0EnTzkh" is the id of the trail document, and "reviews" is the subcollection within "trails". Also, with the above code, we're not specifying an ID for the new review document, but letting Firestore auto-generate one.
We could do this instead, if we wanted to provide an ID for the new review document:
await setDoc(doc(db, "trails", "q2WkYeRXEZWoG0EnTzkh", "reviews", "0"), newReviewData);
In the both of the examples above, we have to specify a collection, then the doc within the collection (which may or may not exist yet), then specify another collection within that doc.
Things can get messy quickly, the subcollections can get difficult to query, and if the parent doc gets deleted, that can leave the subcollection orphaned, making it very difficult to access. That's because deleting a document does not also automatically delete any subcollections that are associated with it.
While this approach most closely maps to creating a one-to-many relationship, we don't really recommend it even though it's listed as a valid option in the Firestore documentation. It certainly is valid — and there are use cases — but be prepared for headaches with this approach.
Using Multiple Collections for Data
The final recommendation, and the one that's probably effective for the most use cases, is to just use multiple collections. In this situation, we'd have separate collections for trails and reviews. In order to create something similar to a one-to-many association, we'd need to manually create the association between a trail and a review in our code. We just need to add a field like trailId to a review. The code for creating an association might look something like this:
await addDoc(collection(db, "reviews"), {trailId: tid, content: "Amazing trail!" })
Here, we add a review that has a trail's id associated with it. At that point, if we wanted to find all reviews associated with a trail, we could make a query to find reviews that have a trailId equal to the trail's id.
In this way, we can still make associations that are somewhat similar to what we might do with a SQL database. Firestore's queries are extremely fast because all records and fields are indexed. A database index is like an index in the back of a book that allows you to quickly find a record without having to search every row in the database. This means it will take about the same amount of time to run a query to grab reviews associated with a specific trail id as it would to just grab the whole collection of reviews.
Remember that NoSQL databases scale well horizontally, so it's fine to have multiple large, shallow collections instead of deeply nested data.
Summary
In this lesson, we've covered three approaches for creating a data structure in a Firestore application. All three have their use cases, but the third generally works best with Firestore's current capacities. As we can see, we can still make associations between different pieces of data in our code. It's just that NoSQL doesn't have a structure to enforce or check these relationships. We are entirely on the hook for creating them on our own.
As always, your use case will determine which kind of data structure works best for your application. In the example above, creating several collections and manually creating associations in the code between documents is probably the best approach.
However, if we were making a game where a user could hold a limited number of items, the first or second approach would probably be better. Having an items property on a character that has a maximum of nine slots would be reasonable — and we'd probably want to return all nine items each time we were pulling up the character anyway.
Creating subcollections for a document might be a solid option if you'll have a relatively limited number of items in that subcollection — but you don't want those results to be returned every single time. If we had an application about books, for example, each book document might have general information such as description and name — but we wouldn't want to include the whole text in the record because it would take a long time to query each book. Instead, we might create a subcollection called chapters that has the text for each chapter. The query for the general description of the book would still be very fast — but if needed, we could do an additional, slower query to get all the text in the subcollection. As long as we didn't want to do a query across all the chapters of all the different books in our application, this would work fine.
If you'd like more information, see Firestore's documentation on data structures. The videos included in the documentation are also recommended.